
一年前,大概流行通过不断强化预设提示词等手段解除gpt限制生成相关文本,其中明显感觉gpt4更容易绕过审查,且生成质量较高,只是成本太高。
最近看到了gpt4omini的api价格十分便宜,再次搜索相关项目,发现基本都销声匿迹、没有更新了。
继续搜索发现可以本地跑模型生成文本。而考虑到设备限制(4090及以下),大多数用户适合使用KoboldCpp ——支持windows,用户友好,有丰富的 API 支持(可以对接语音合成等)的基于GGML/GGUF模型的推理框架。
![图片[1]-使用KoboldCpp简单运行本地大语言模型,替代ChatGPT生成NSFW文本-THsInk](https://www.thsink.com/wp-content/uploads/2024/07/image-1024x559.png)
1. 下载安装KoboldCpp
https://github.com/LostRuins/koboldcpp/releases
我用4090,选择koboldcpp_cu12.exe,没有cuda核心等情况参照说明下载其他相应版本。
要使用,请下载并运行koboldcpp.exe,这是一个单文件 pyinstaller。
如果您不需要 CUDA,则可以使用小得多的koboldcpp_nocuda.exe。
如果您有较新的 Nvidia GPU,则可以使用 CUDA 12 版本koboldcpp_cu12.exe (大得多,速度稍快)。
如果您使用的是 Linux,请选择适当的Linux二进制文件(而不是 exe)。
如果您使用的是 AMD,您可以尝试YellowRoseCx 的 fork中的koboldcpp_rocm
2. 下载GGUF语言模型
可能有些模型是向nsfw特化的,我没有对比很多,随便下了几个。网上的模型大部分是英语的,中文模型好像选择也没有很多。
CausalLM-14B
https://huggingface.co/tastypear/CausalLM-14B-DPO-alpha-GGUF/tree/mainYi-34B-Chat
https://huggingface.co/TheBloke/Yi-34B-Chat-GGUF/resolve/main/yi-34b-chat.Q5_K_M.gguf诸如此类,可以多下几个对比一下。
3. 预设提示词/人物卡
其实我是先搜到了这个网站,再了解到KoboldCpp。上述网站为英文预设,可以通过此网站编辑或自行生成配置/人物卡:
https://zoltanai.github.io/character-editor/
另外,在KoboldCpp的webui也可以手动添加提示词。
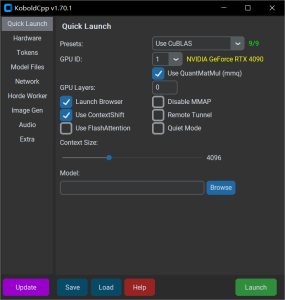
4. 启动、配置
运行KoboldCpp,在model处选择第2步下载的模型后点击launch即可快速启动。详细的配置参数可以在此找到https://github.com/LostRuins/koboldcpp/wiki
![图片[2]-使用KoboldCpp简单运行本地大语言模型,替代ChatGPT生成NSFW文本-THsInk](https://www.thsink.com/wp-content/uploads/2024/07/image-1.png)
有大佬取消勾选contextshift(Context Shifting是Smart Context的改进版本,仅适用于GGUF模型)并勾选flashattention(--flashattention可用于在使用 CUDA/CuBLAS 运行时启用,从而可以提高速度并提高内存效率。),并将Tokens选项卡中的Quantize KV Cache设置为4Bit,不知道有什么区别,没有对比过。
启动后会自动弹出webui,可以添加人物卡或手动添加预设
![图片[3]-使用KoboldCpp简单运行本地大语言模型,替代ChatGPT生成NSFW文本-THsInk](https://www.thsink.com/wp-content/uploads/2024/07/image-2-1024x704.png)
顶部settings处还可以进行更多设置,比如提高输出文本量
![图片[4]-使用KoboldCpp简单运行本地大语言模型,替代ChatGPT生成NSFW文本-THsInk](https://www.thsink.com/wp-content/uploads/2024/07/image-3-1024x794.png)
然后开始聊天。
5. 体验总结
服从程度明显超过gpt4,但有时的文学性和创造力还是不如gpt4,可能受限于模型吧。
相关折腾
2024年12月更新:半年~一年前老旧的自托管模型还是不够智能,远不如当前的claude。claude破限配合SillyTavern可以添加人物设置+多个世界设置,挺有意思。
参考
https://wiki.pygmalion.chat/
https://github.com/LostRuins/koboldcpp/wiki
https://www.youtube.com/@v3ucn
https://www.bilibili.com/read/cv23877210/
https://www.jian27.com/html/1306.html


![表情[xiaojiujie]-THsInk](https://www.thsink.com/wp-content/themes/zibll/img/smilies/xiaojiujie.gif)
暂无评论内容